
09009
[DB] GROUP BY, HAVING, Pivot table 본문
그룹 함수
여러 행 또는 테이블 전체의 행에 대해 함수가 적용되어 하나의 결과값을 가져오는 함수
- 그룹 함수 종류 : MAX, MIN, SUM, AVG, COUNT
• GROUP BY절을 이용하여 그룹 당 하나의 결과가 주어지도록 그룹화 가능
• HAVING절을 이용하여 그룹 함수를 가지고 조건비교를 할 수 있다.
• COUNT(*)를 제외한 모든 그룹함수는 NULL값을 고려하지 않는다.
• MIN, MAX 그룹함수는 모든 자료형에 대해서 사용 할 수 있다.
그룹 함수의 종류
COUNT : 검색된 행의 수를 반환
MAX : 컬럼 중에서 최대값을 반환
MIN : 컬럼중의 최솟값을 반환
AVG : 평균값을 반환
SUM : 검색된 컬럼의 합을 반환
GROUP BY절
• 특정한 컬럼의 테이터들을 다른 데이터들과 비교해 유일한 값에 따라 그룹을 만든다
• GROUP BY절을 이용하여 한 테이블의 행들을 원하는 그룹으로 나눈다
• Column명을 GROUP함수와 SELECT절에 사용하고자 하는 경우 GROUP BY 뒤에 Column명을 추가하면 된다.
!! 그룹함수와 같이 사용하는 column명은 반드시 group by절 뒤에 있어야 한다 !!
-- ! 그룹함수와 같이 사용하는 칼럼은 반드시 group by에 있어야 한다. !
select deptno, sum(sal), avg(sal), max(sal), min(sal), count(sal) from emp group by deptno;
-- select deptno, sum(sal), avg(sal), max(sal), min(sal), count(sal) from emp; 에러 발생!! 주의 !!
- sum(comm)/ count(comm) : 커미션을 받는 사람만, comm이 null인 사람은 제외
- sum(comm)/count(*), sum(nvl(comm,0))/count(*) : comm을 안 받는 사람까지 합계
select sum(comm), avg(comm),sum(comm)/count(comm), sum(comm)/count(*), sum(nvl(comm,0))/count(*), avg(nvl(comm,0)) from emp;
실습 예제
-- 부서별 급여합계, 급여 평균
-- 업무별 최대 급여, 최소 급여
-- 업무가 manager이거나 analyst인 사람의 급여합계, 급여평균
-- 부서명, 급여합계, 최대 급여
-- 부서명, 근무지, 급여합계, 인원수 부서명순
-- 부서명, 최대급여, 최소급여, 인원수 comm이 null이 아닌 사람
-- 업무별 최대급여, 최소급여, 인원수 업무별 정렬
-- 부서명, 업무명, 최대급여, 최소급여, 인원수 부서명순, 업무별 순 정렬
-- 전직원 급여합계, 최대급여, 최소급여, 인원수
-- 부서별 급여합계, 급여 평균
select deptno, sum(sal), round(avg(sal)) from emp group by deptno order by deptno;
-- 업무별 최대 급여, 최소 급여
select job, max(sal), min(sal) from emp group by job;
-- 업무가 manager이거나 analyst인 사람의 급여합계, 급여평균
select job, sum(sal), round(avg(sal)) from emp where lower(job) in ('manager','analyst') group by job;
-- 부서명, 급여합계, 최대 급여
select dname, sum(sal), max(sal) from emp e join dept d
on e.deptno = d.deptno group by dname;
-- 부서명, 근무지, 급여합계, 인원수 부서명순
select dname, loc, sum(sal), count(*) 인원수 from emp e join dept d
on e.deptno = d.deptno group by dname, loc order by dname;
-- 부서명, 최대급여, 최소급여, 인원수 comm이 null이 아닌 사람
select dname, max(sal), min(sal), count(*) from emp e join dept d
on e.deptno = d.deptno where comm is not null group by dname;
-- 업무별 최대급여, 최소급여, 인원수 업무별 정렬
select job, max(sal), min(sal), count(*) from emp group by job order by job;
-- 부서명, 업무명, 최대급여, 최소급여, 인원수 부서명순, 업무별 순 정렬
select dname, job, max(sal), min(sal), count(*) from emp e join dept d
on e.deptno = d.deptno group by dname, job order by dname, job;
-- 전직원 급여합계, 최대급여, 최소급여, 인원수
select sum(sal), max(sal), min(sal), count(*) from emp;
HAVING절 - 그룹함수에 대한 조건
select 컬럼,... from table명,... where 조건(테이블로부터 추출)
group by 컬럼/식 having 조건(그룹함수에 대한 조건) order by 컬럼/순서/별칭/식;※ 참고) GROUP BY절에는 순서, 별칭을 작성할 수 없다.
에러발생 코드
-- 부서별 인원수가 4명 이상인 부서의 최대급여, 급여합계, 인원수
select deptno, max(sal), sum(sal), count(*) from emp where count(*) >= 4 group by deptno; -- 에러 발생위 소스코드는 에러가 발생한다.
where절은 테이블로부터 데이터를 추출하는 조건을 작성한다.
즉, where절은 조건에 맞게 데이터를 추출하기를 시작하는데 where절에서 이미 그룹함수에 대한 조건을 작성해버리면 당연히 오류가 발생한다. (다 꺼내봐야 알 수 있는데 아직 안꺼냈으므로)
→ HAVING 절에 그룹함수에 대한 조건을 작성하여 해결해야 한다.
!! HAVING은 그룹함수에 대한 조건 (WHERE 절: 그룹에 대한 조건, HAVING: 그룹함수에 대한 조건) !!!
!! 그룹에 대한 조건은 WHERE절에 작성하면 안된다 !!
올바른 소스코드
select deptno, max(sal), sum(sal), count(*) from emp group by deptno having count(*) >= 4;
실습 예제
-- 부서별, 급여합계, 최대급여, 최대급여가 2900 이상
-- 업무별, 급여합계, 최대급여, 인원수가 3명 이상인 업무
-- 업무별 최대급여 중 가장 많은 급여와 가장 적은 급여
-- 부서별 급여합계 중에 최소급여, 최대급여, 최대인원
-- 부서명, 급여합계 급여합계가 9000이상인 부서
-- 부서명, 평균급여(소숫점 1자리 반올림) 평균 급여가 2000 이상인 부서 부서명순 정렬
-- 부서별, 급여합계, 최대급여, 최대급여가 2900 이상
select deptno, sum(sal), max(sal) from emp group by deptno having max(sal) >= 2900;
-- 업무별, 급여합계, 최대급여, 인원수가 3명 이상인 업무
select job, sum(sal), max(sal), count(*) from emp group by job having count(*) >= 3;
-- 업무별 최대급여 중 가장 많은 급여와 가장 적은 급여
select max(max(sal)), min(max(sal)) from emp group by job;
-- 부서별 급여합계 중에 최소급여, 최대급여, 최대인원
select min(sum(sal)), max(sum(sal)), max(count(*)) from emp group by deptno;
-- 부서명, 급여합계 급여합계가 9000이상인 부서
select dname, sum(sal) from emp e join dept d on e.deptno = d.deptno
group by dname having sum(sal) >= 9000;
-- 부서명, 평균급여(소숫점 1자리 반올림) 평균 급여가 2000 이상인 부서 부서명순 정렬
select dname, round(avg(sal), 1) from emp e join dept d on e.deptno = d.deptno
group by dname having avg(sal) >= 2000 order by 1;
-- EMP 테이블에서 인원수,최대 급여,최소 급여,급여의 합을 계산하여 출력하는 SELECT 문장을 작성하여라.
-- EMP 테이블에서 각 업무별로 최대 급여,최소 급여,급여의 합을 출력하는 SELECT 문장을 작성하여라.
-- EMP 테이블에서 업무별 인원수를 구하여 출력하는 SELECT 문장을 작성하여라.
-- EMP 테이블에서 최고 급여와 최소 급여의 차이는 얼마인가 출력하는 SELECT 문장을 작성하여라.
-- EMP 테이블에서 인원수,최대 급여,최소 급여,급여의 합을 계산하여 출력하는 SELECT 문장을 작성하여라.
select count(*), max(sal), min(sal), sum(sal) from emp;
-- EMP 테이블에서 각 업무별로 최대 급여,최소 급여,급여의 합을 출력하는 SELECT 문장을 작성하여라.
select job, max(sal), min(sal), sum(sal) from emp group by job;
-- EMP 테이블에서 업무별 인원수를 구하여 출력하는 SELECT 문장을 작성하여라.
select job, count(*) from emp group by job;
-- EMP 테이블에서 최고 급여와 최소 급여의 차이는 얼마인가 출력하는 SELECT 문장을 작성하여라.
select max(sal) - min(sal) 급여차이 from emp;
피벗 테이블

select deptno, sum(decode(job,'CLERK',sal)) CLERK,
sum(decode(job,'MANAGER',sal)) MANAGER,
sum(decode(job,'PRESIDENT',sal)) PRESIDENT,
sum(decode(job,'ANALYST',sal)) ANALYST,
sum(decode(job,'SALESMAN',sal)) SALESMAN from emp group by deptno order by deptno;

-- 세로 합계
select deptno, sum(decode(job,'CLERK',sal)) CLERK,
sum(decode(job,'MANAGER',sal)) MANAGER,
sum(decode(job,'PRESIDENT',sal)) PRESIDENT,
sum(decode(job,'ANALYST',sal)) ANALYST,
sum(decode(job,'SALESMAN',sal)) SALESMAN,
sum(sal)합계 from emp group by deptno order by deptno;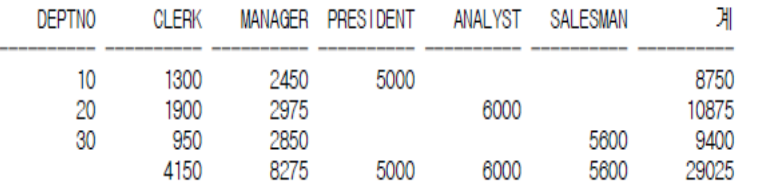
-- 가로 합계
select deptno, sum(decode(job,'CLERK',sal)) CLERK,
sum(decode(job,'MANAGER',sal)) MANAGER,
sum(decode(job,'PRESIDENT',sal)) PRESIDENT,
sum(decode(job,'ANALYST',sal)) ANALYST,
sum(decode(job,'SALESMAN',sal)) SALESMAN,
sum(sal) 합계 from emp group by rollup(deptno) order by deptno;
-- EMP 테이블에서 아래의 결과를 출력하는 SELECT 문장을 작성하여라

-- EMP 테이블에서 아래의 결과를 출력하는 SELECT 문장을 작성하여라

-- EMP 테이블에서 아래의 결과를 출력하는 SELECT 문장을 작성하여라

select to_char(hiredate, 'yy') H_YEAR, count(*), min(sal), max(sal), avg(sal), sum(sal)
from emp group by to_char(hiredate, 'yy') order by H_YEAR;
-- 계속 틀리는 문제 --
select sum(count(*)) TOTAL, sum(decode(to_char(hiredate,'yy'),80,count(*))) "1980",
sum(decode(to_char(hiredate,'yy'),81,count(*))) "1981",
sum(decode(to_char(hiredate,'yy'),82,count(*))) "1982",
sum(decode(to_char(hiredate,'yy'),83,count(*))) "1983" from emp group by hiredate;
select job, sum(decode(deptno,10,sal)) "Deptno 10", sum(decode(deptno,20,sal)) "Deptno 20",
sum(decode(deptno,30,sal)) "Deptno 30", sum(sal) Total from emp group by job order by job;
ROLLUP과 CUBE
select deptno, job, sum(sal) from emp group by rollup(deptno, job) order by deptno;
select deptno, job, sum(sal) from emp group by CUBE(deptno, job) order by deptno;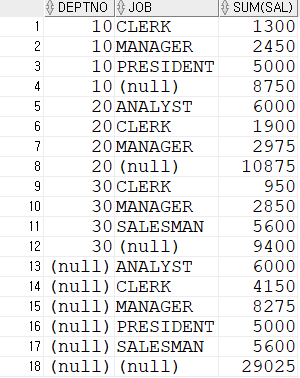
-- 사원테이블에서 최대급여, 최소급여, 전체 급여합, 평균을 구하시오
-- 사원테이블에서 부서별 인원수를 구하시오
-- 사원테이블에서 부서별 인원수가 6명 이상인 부서코드를 구하시오
-- 사원테이블에서 다음과 같은 결과가 나오게 하시오

-- 사원테이블에서 급여가 높은 순서대로 등수를 부여하여 다음과 같은 결과가 나오게 하시오.
힌트 self join, group by, count사용

-- 사원테이블에서 최대급여, 최소급여, 전체 급여합, 평균을 구하시오
select max(sal), min(sal), sum(sal), round(avg(sal)) from emp;
-- 사원테이블에서 부서별 인원수를 구하시오
select deptno, count(*) from emp group by deptno order by deptno;
-- 사원테이블에서 부서별 인원수가 6명 이상인 부서코드를 구하시오
select deptno, count(*) from emp group by deptno having count(*) >= 6;
-- 사원테이블에서 다음과 같은 결과가 나오게 하시오
select dname, sum(decode(job,'CLERK',sal)) CLERK,
sum(decode(job,'MANAGER',sal)) MANAGER,
sum(decode(job,'PRESIDENT',sal)) PRESIDENT,
sum(decode(job,'ANALYST',sal)) ANAYLST,
sum(decode(job,'SALESMAN',sal)) SALESMAN
from emp join dept on emp.deptno = dept.deptno group by dname;
-- 사원테이블에서 급여가 높은 순서대로 등수를 부여하여 다음과 같은 결과가 나오게 하시오. 힌트 self join, group by, count사용
select e1.ename, count(e2.sal)+1 등수 from emp e1 left outer join emp e2
on e1.sal < e2.sal group by e1.ename order by 등수;
/
5/6
'DB > Oracle' 카테고리의 다른 글
| [DB] EXISTS (0) | 2023.04.01 |
|---|---|
| [DB] Subquery (0) | 2023.03.27 |
| [DB] (중요) Join (0) | 2023.03.25 |
| [DB] to_char, substr, round, case when, decode (0) | 2023.03.25 |
| [DB] BETWEEN, IN, LIKE, ASC / DESC (0) | 2023.03.25 |